User Guide
Requirements
The only packages required to run the code are:
In order to run the sample visualization script, users need:
- Matplotlib (2D plots)
- Pyvista (3D plots)
Note, however, that these packages are not required to run the code itself and users can use any Python data visualization library they prefer.
Download
The BxC toolkit is available at this Github repository and can easily be obtained by cloning the online repository:
git clone https://github.com/danielamaci/bxc.github.io
Run the code
The code files are all stored in the folder code of the cloned repository. The user-controlled parameters are all contained in the file parameters.py. Once the desired parameters have been chosen, run:
python BxC.py
Note: The default BxC.py will save the generated data cube of turbulent magnetic field in your root directory. No statistical analysis or visualization is pre-implemented, in order to let users free to use their own routines.
The parameters.py file
All the parameters that are user-controlled can be found and modified in the parameters.py file. Here is an overview of what the file contains.
First, all the imports are included in here. Afterwards you can find all the parameters determining the general properties of the field (resolution, background topologies, and the definition of the white noise vector).
Note: All the published results are generated with seed_wn=130.

In the last part of the file, you find the input parameters of the modified Biot-Savart law. These parameters are responsible for the customization of the power spectrum, according to the relations written in this table.

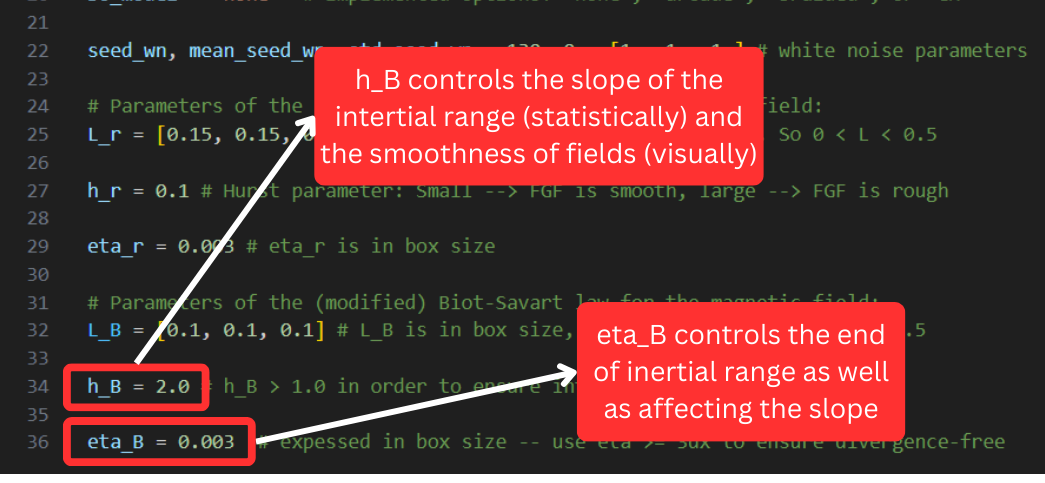
Power spectrum customization
Here you can find the set of relations telling how the power spectrum varies as the user varies the parameters of the code. For more details on the parameter study that has been conducted see the article.
| Relations | Schematic representation |
|---|---|
 |
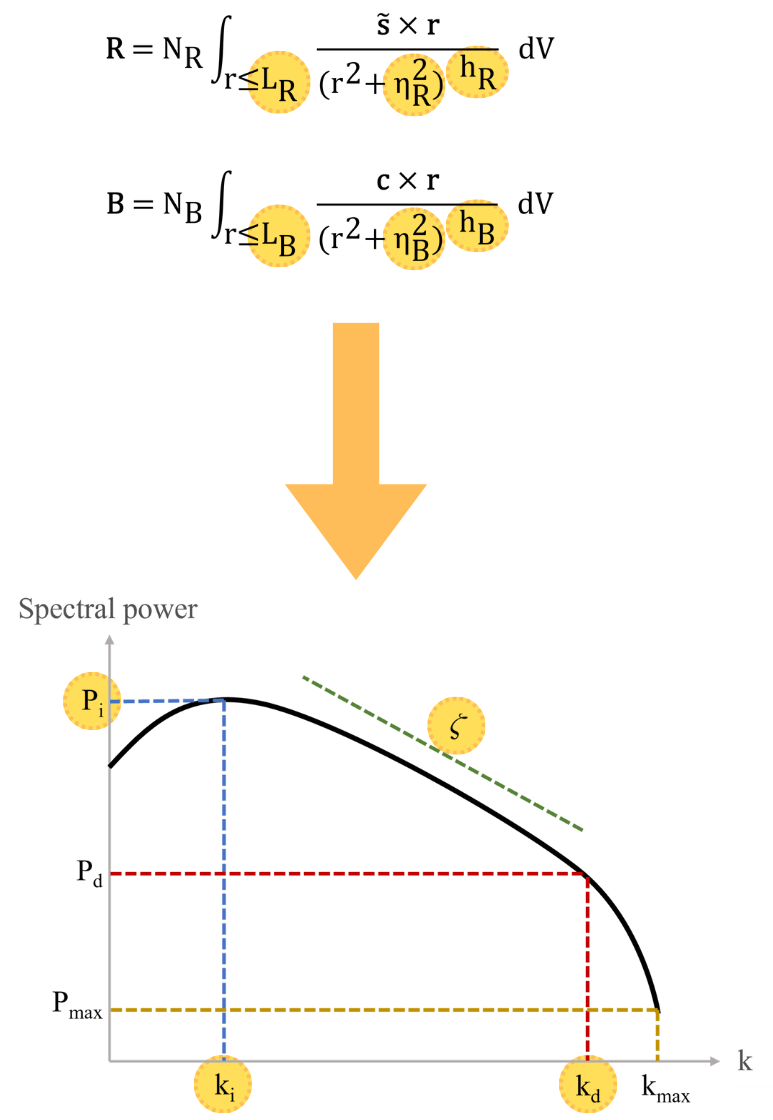 |
The notation (par;*), where par = LB, hB, or ηB, is used when a feature does not depend on “par” only, but the other parameters on which it depends are kept constant to the reference value.